
《この記事の前半はnoteに投稿されています。是非ご覧ください。》

標準化が変えるゲームのルール──UCIeという共通語
チップレット技術の普及における最大の課題の一つが「接続の規格問題」でした。各社が独自のインターフェースを使っていれば、異なるメーカーのチップレットを組み合わせることはできません。これは半導体のサプライチェーン(供給網)を柔軟にするうえで大きな障壁となっていました。
この課題に対応するために2022年3月に設立されたのが「UCIe(Universal Chiplet Interconnect Express)コンソーシアム」です。AMD、Intel、ARM、TSMC、Samsung、Qualcomm、Meta、Microsoft、Google Cloudなど当初10社でスタートし、現在は80社を超える企業が参画しています(参照:マイナビニュース)。
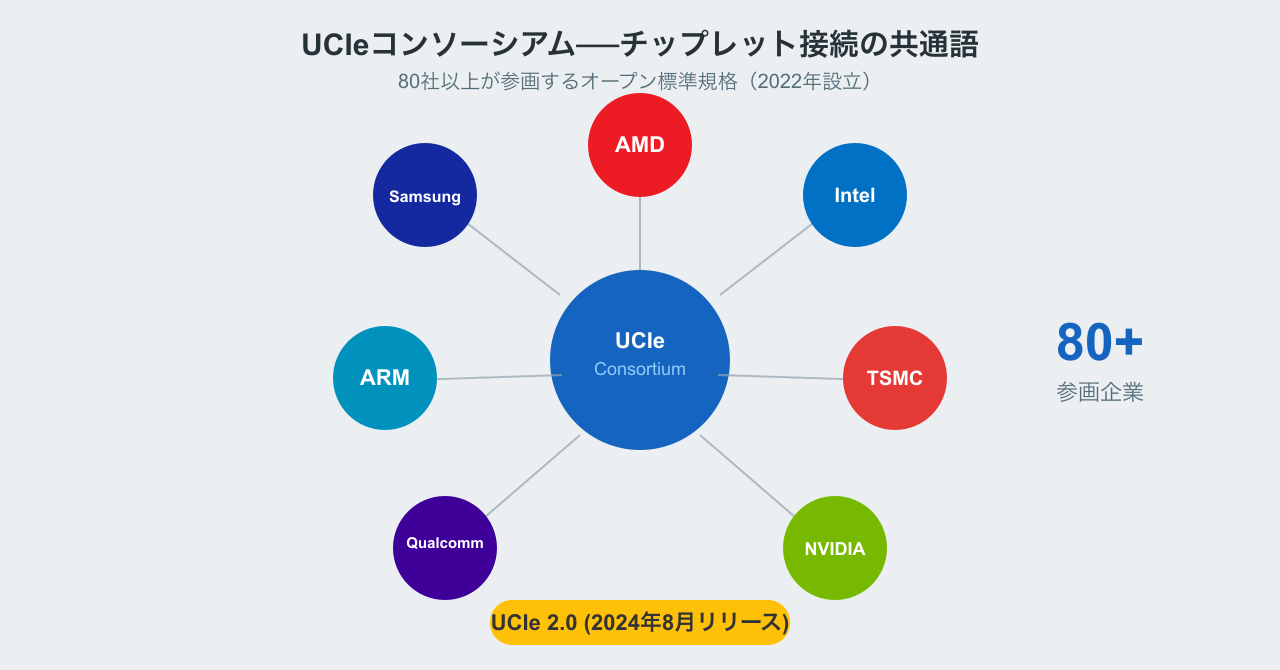
UCIeはチップレット間の接続インターフェースを標準化するもので、PCIe(PCI Express)の成功例に倣ったオープンな規格です。2024年8月には「UCIe 2.0」仕様がリリースされ、3Dパッケージング(チップを縦に積み重ねる技術)のサポートや、帯域幅・電力効率の大幅な向上が図られました(参照:PC Watch)。
UCIe 2.0の意義は大きく、ハイブリッドボンディング(従来のはんだバンプに代わる微細な接続技術)への対応が進んだことで、チップレット間の通信速度と電力効率が飛躍的に向上しました。また3D積層に対応したことで、異なるメーカーのチップを「横に並べる」だけでなく「縦に重ねる」構成も標準仕様に含まれるようになりました。
この標準化が進むことで、半導体業界のサプライチェーンは「部品調達型」への転換が加速します。ちょうどPCの組み立てで異なるメーカーのパーツを組み合わせられるように、将来的にはAMDのCPUチップレットとNVIDIAのGPUチップレットを組み合わせるような構成も、理論的には可能になります。
AMD・Intel・NVIDIAの三者三様の戦略
チップレット時代の覇権争いは、各社の戦略の違いが非常に鮮明です。
AMDの戦略──チップレットネイティブな設計思想
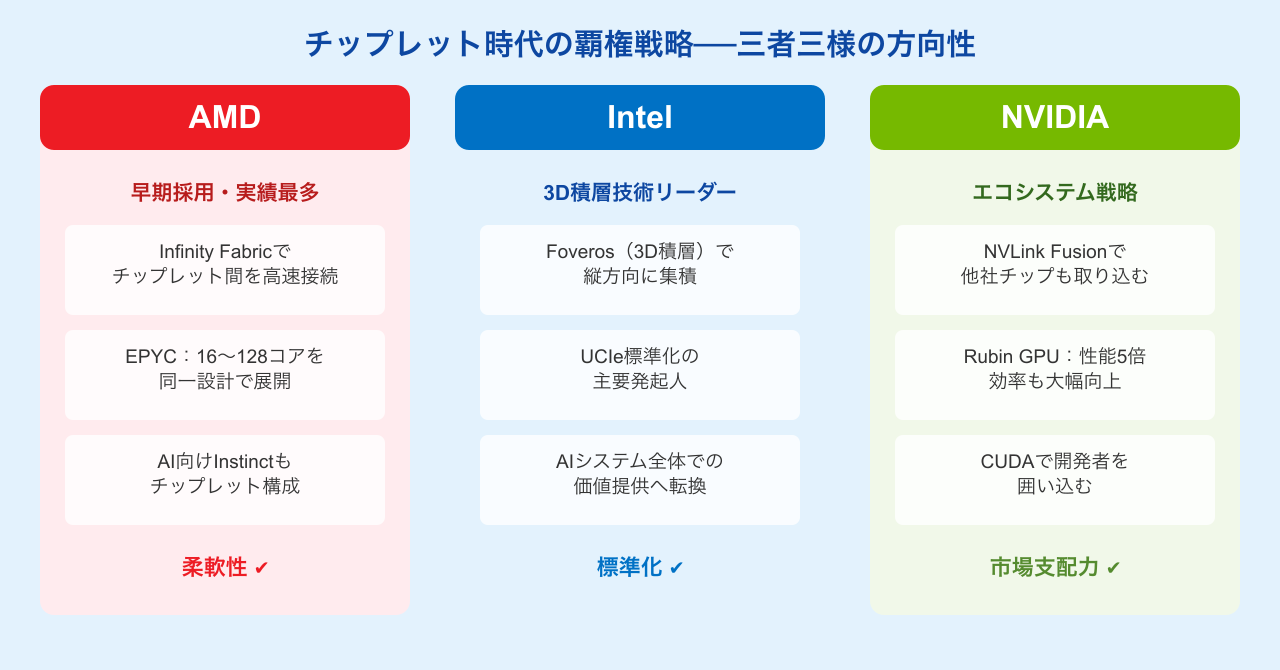
AMDはチップレット技術を早期に採用し、EPYC(サーバー向け)、Ryzen(デスクトップ・ノートPC向け)の両ラインで一貫して採用しています。特にサーバー向けEPYCは、2〜16枚の演算用チップレットと入出力用チップレットを組み合わせることで、16コアから最大128コアまで同一アーキテクチャから展開する柔軟な設計を実現しています(参照:日経クロステック)。
また独自技術「Infinity Fabric(インフィニティ ファブリック)」は、チップレット間を高速接続するための専用インターフェースで、複数のチップレットをまとめて1つのプロセッサとして機能させるうえで中核的な役割を担っています。AMDのAIアクセラレータ「Instinct」シリーズにもチップレット構造が採用されており、AI向け半導体市場でのポジション確立も進めています。
Intelの戦略──Foverosと3D積層への注力
Intelはチップレット関連技術として「EMIB(Embedded Multi-die Interconnect Bridge)」と「Foveros(フォベロス)」という2つの独自技術を持っています。EMIBはチップを横に並べて高速接続する2.5D技術、Foverosはチップを縦に積み重ねる3D積層技術です。
UCIeコンソーシアムの主要発起人の一つであり、標準化においては業界をリードしてきたIntelですが、近年は製造プロセスの競争力低下という課題を抱えています。2025年の世界半導体企業売上ランキングでは、NVIDIAの1,478億ドルに対してIntelは334億ドルと大きく引き離されており(参照:セミコンポータル)、AIチップ「Gaudi 3」の市場投入でも苦戦が続いています。
2026年に向けてはデータセンター向けAIシステム「Jaguar Shores」の投入を計画していますが、単体チップでの競争から、最適化されたシステム全体での価値提供へと戦略を転換しています。
NVIDIAの戦略──エコシステムで囲い込む「AIファクトリー」構想
NVIDIAは「NVLink Fusion(エヌブイリンク・フュージョン)」という超高速インターコネクト技術を活用し、顧客が独自設計のチップとNVIDIA製GPUをシームレスに組み合わせられる「AI Factory(AIファクトリー)」構想を推進しています(参照:arpable.com)。
次世代GPU「Rubin(ルービン)」のロードマップも公表されており、演算性能(FLOPS)で現行Blackwellの5倍を実現しながら、トランジスタ数の増加は1.6倍に抑えるという効率向上が特徴です。これもチップレット技術による最適化の成果といえます。
NVIDIAの強みは、チップの性能だけでなく「CUDAエコシステム」という開発者向けのソフトウェア基盤にあります。チップレット時代においても、NVIDIAはハードウェアとソフトウェアを一体で提供することで、競合の参入障壁を作り続けています。
TSMCが握る製造の覇権
チップレット時代の製造を語るうえで欠かせないのが、TSMC(台湾積体電路製造)の存在です。2025年1〜9月の世界半導体企業売上では2位の887億ドルを記録。AMD、Apple、NVIDIA、Qualcommなど主要チップメーカーの製造を担うTSMCは、チップレット技術の実用化における中核的なプレーヤーです(参照:セミコンポータル)。
TSMCの「CoWoS(Chip on Wafer on Substrate)」技術は、HBM(高帯域メモリ)と演算チップレットを同一基板上に集積するもので、NVIDIAのBlackwell GPUにも採用されています。また「InFO(Integrated Fan-Out)」と呼ばれる先進パッケージング技術は、Appleのモバイルチップなどで実績を積んでいます。
製造だけでなく、TSMCはUCIeコンソーシアムにもグループ会社として参画し、標準化活動の推進にも関与しています。チップレットの普及は必然的にTSMCのような高度なパッケージング技術を持つファウンドリ(製造専業企業)の役割をさらに重要にするため、TSMCの競争優位は今後さらに強化される見通しです。
市場規模と今後の展望
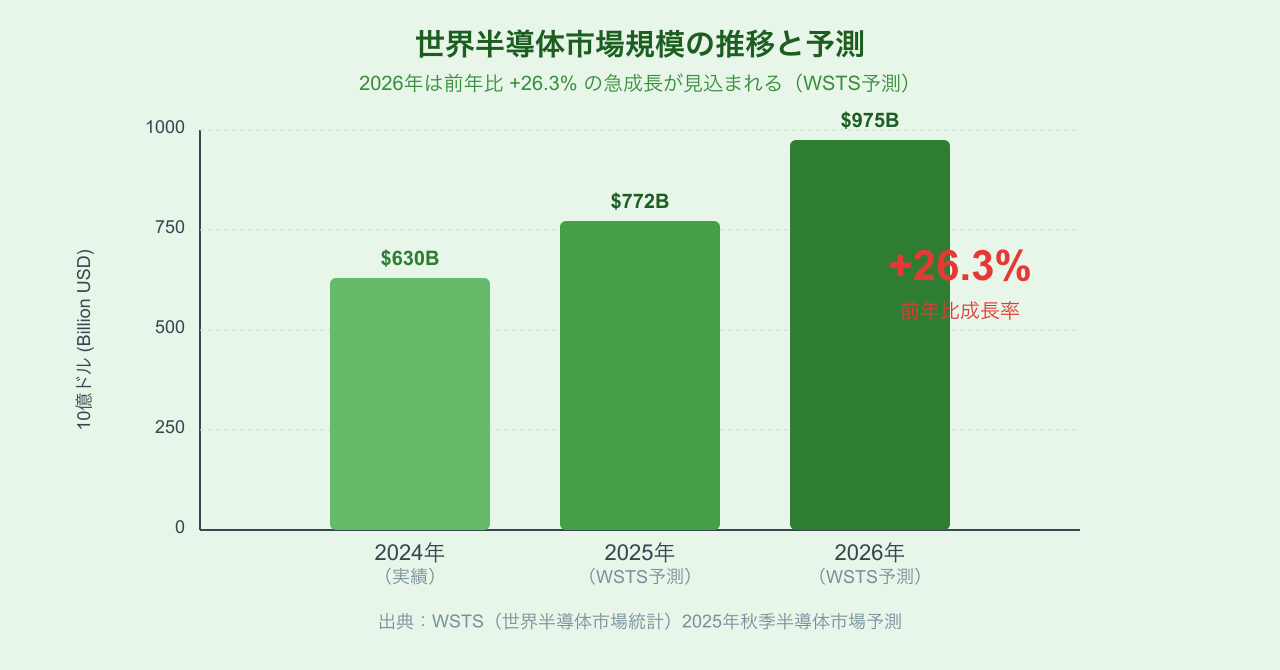
世界半導体市場は急拡大が続いており、WSTSの予測では2025年に7,722億ドル、2026年には9,754億ドル(前年比+26.3%)に達するとされています(参照:coevo/Aconnect)。
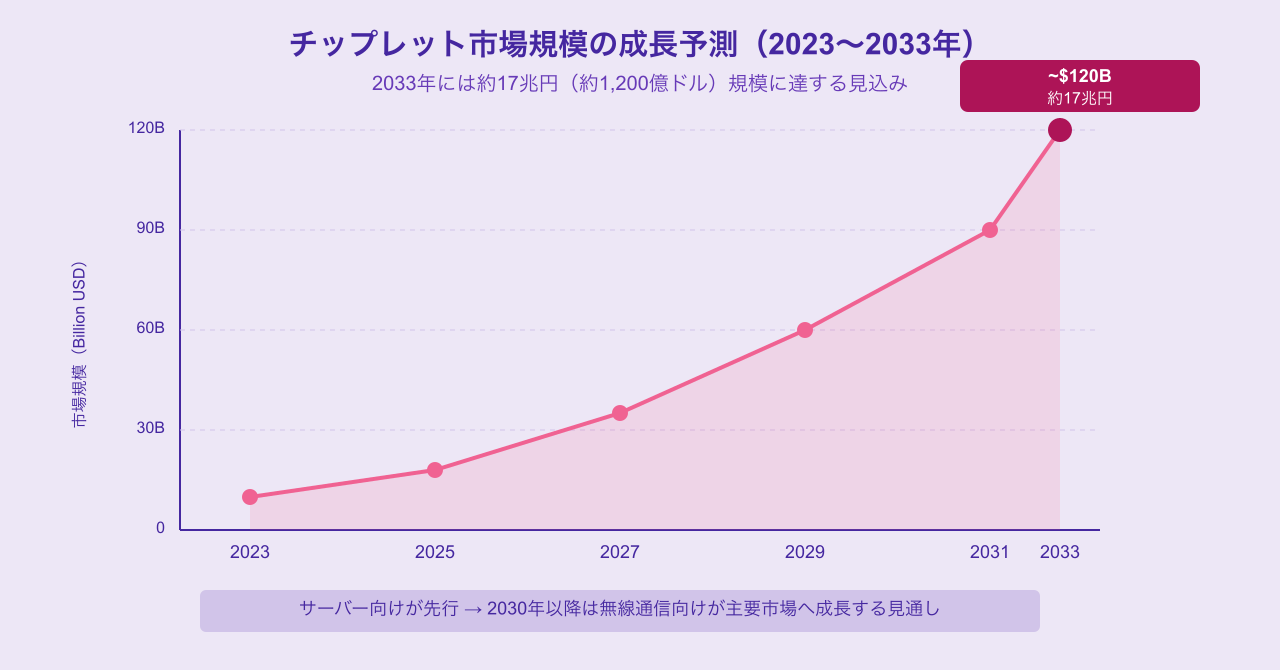
チップレット市場は特に高い成長が見込まれており、2033年には約17兆円規模に拡大するとの予測もあります。市場を牽引するのは当面はサーバー・データセンター向けで、その後は自動車・無線通信向けへと需要の裾野が広がっていく見込みです(参照:三井物産グローバル研究所)。
2026年に注目すべき動向は複数あります。NVIDIAの次世代AIサーバー向けGPU「Rubin」の量産開始、Intelの「Panther Lake(パンサーレイク)」を搭載したノートPC向けプロセッサのリリース、AMDの「Gorgon Point(Ryzen AI 400シリーズ)」の登場などが予定されており、いずれもチップレット設計が基本となっています。
ただし、2026年はメモリ価格の高騰と供給不足という別の問題が表面化しており、AI向けGPUへの生産リソース集中による一般向けメモリの品薄が、PC市場全体の価格高騰につながっています。チップレット技術が製造コストを最適化するとしても、その恩恵がコンシューマー向けに届くまでには時間がかかる可能性があります。
まとめ──「どこで作るか」から「どう組み合わせるか」へ
チップレット技術の台頭は、半導体競争の本質を変えつつあります。かつての競争は「いかに微細なプロセスで大きなチップを一枚岩で作れるか」でした。しかし今は「いかに最適なチップレットを組み合わせて、全体として高い性能・コスト効率を実現できるか」に移っています。
AMD、Intel、NVIDIAはそれぞれ異なるアプローチでこの時代に挑んでいますが、共通しているのは「チップレットなしの未来はない」という認識です。そしてUCIeという共通規格の整備が進むことで、業界全体の分業体制はさらに深化し、これまで半導体業界に参入できなかった新しいプレーヤーが台頭するチャンスも広がっています。
「ムーアの法則の終わり」は半導体の終わりではありませんでした。それは、より賢い設計の時代の幕開けだったのです。


コメント